
고정 헤더 영역
상세 컨텐츠
본문
React를 Frontend로 사용하면서 상태 관리를 좀 더 효율적으로 할 수 있는 방법이 없을까?
있다면 어떻게 하지?
그리고 처음 설계를 진행하고, 개발을 완료해 나중에 배포했을 때, 사용자들이 요구한 사항들을 추가로 개발하게 될 때에는 상태 관리는 어쩌지? 하는 고민을 해본 적이 있었다.
이번 ifKakao dev 컨퍼런스에서 진행 한 세션 중 가장 적합한 것 같아 보여 공유하려고 한다.
이 세션은 카카오의 My 구독 서비스에서 Redux를 React-Query로 전환한 이유와 과정을 공유한 내용이다.
카카오에서 이와 같은 작업을 진행하게 된 계기는 위의 고민과 같이 처음 설계할 때와 많이 달라진 기능 때문이었다고 한다. 처음엔 카카오톡 데이터 백업 / 이모티콘 플러스를 구독하기 위한 과정 또는 구독 서비스를 확인할 수 있는 기능만 있었는데 나중에 인앱 결제, 이용권, 구독 변경과 같은 기능들이 추가되면서 전체적인 코드 측면에서 개선이 필요해서 진행하게 되었다고 한다.
이 세션에서는 어떻게 진행했는지 다음과 같이 4단계로 나눠서 설명을 한다.
1. React-Query 알아보기
2. Redux에서 React-Query로 전환 이유
3. React-Query로의 전환 과정
4. 정리
<1. React-Query 알아보기>
React-Query란?
프로젝트에서 API 요청을 보낼 때 필요한 부분이 데이터 패칭, 캐싱, 동기화 부분이 있는데 이를 쉽게 만들어주는 라이브러리이다.
그럼, React-Query 없이 react 자체만으로는 데이터 패칭, 캐싱, 동기화가 안되나? 하는 의문이 생긴다. 다음은 React-Query가 가지고 있는 핵심기능을 React로만 구현한 코드이다.
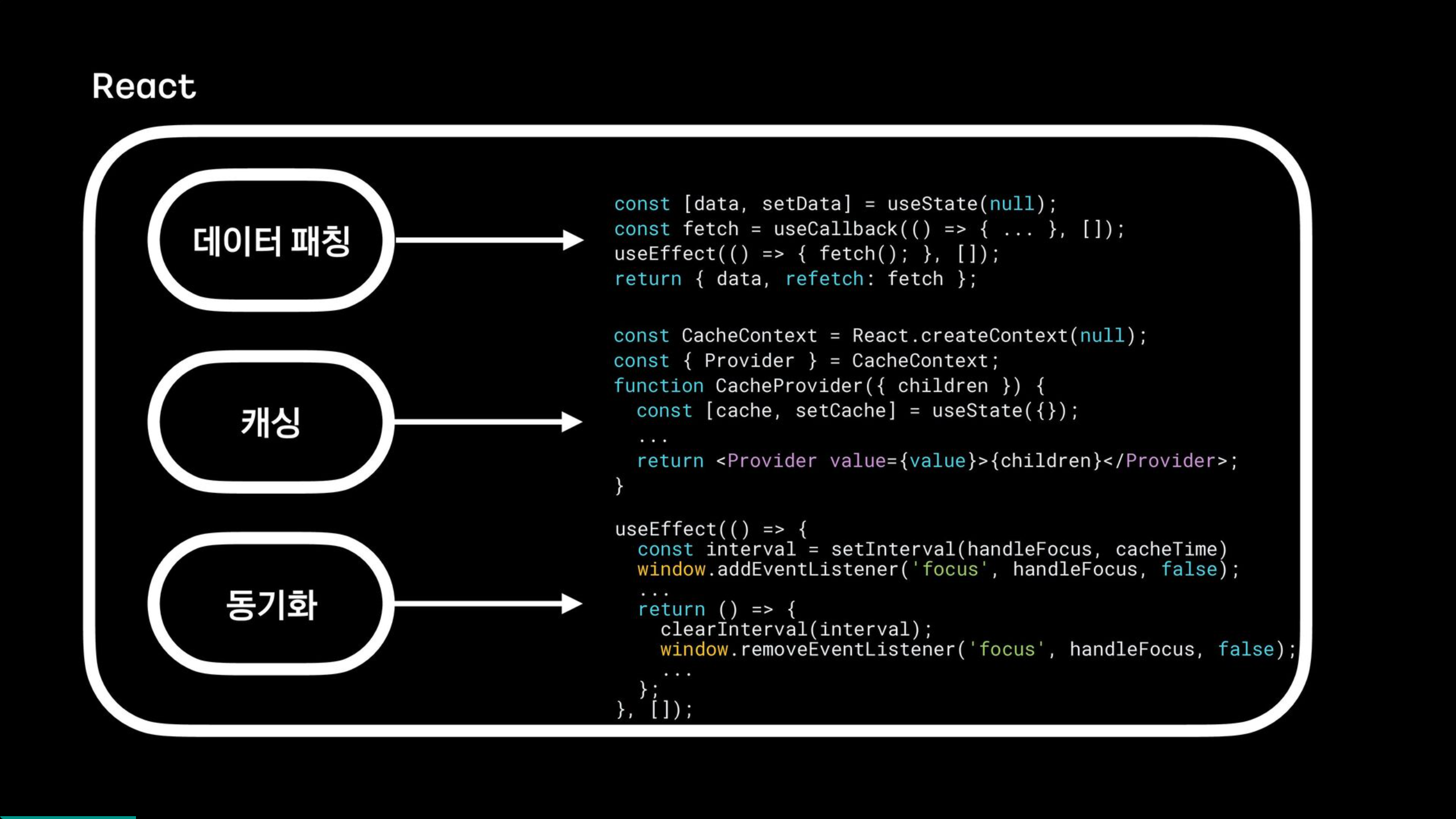
데이터 패칭은 useState, useCallback, useEffect 조합으로 디패치까지 가능한 형태의 커스텀 훅을 만들 수 있다.
캐싱을 구현하기 위해서는 react의 context api 조합으로 커스텀 훅을 어디서나 호출하고 캐싱 데이터를 가져오도록 할 수 있다.
동기화에서 React-Query는 여러 가지 트릭을 이용해 사용자가 인지하는 순간에 데이터를 새로 가져오도록 되어있는데 이는 React의 useEffect와 setInterval, 윈도우의 포커스와 같은 특정한 이벤트 조합으로 데이터를 일정 시간마다 혹은 특정 조건으로 가져오도록 구현할 수 있다.
이렇게 React로도 구현이 가능한데 왜 React-Query를 사용하나?를 생각해보면 이렇게 대표적인 기능들을 하나하나 React로 구현하는 것만으로도 여러 테스트가 필요하고 그만큼의 시간이 더 들게 된다.
또한, 이 과정에서 React는 context api, useState, cashing, error handling 등 너무 많은 고려사항을 가져가야 한다.
반면에 React-Query는 Query-Client와 함께 useQuery 하나, useMutation 하나로 대신할 수 있다는 장점이 있다.
React는 React-Query 대비 안정성을 확보하기엔 어려움이 있어 자체적으로 구현한 훅을 이용하기보다는 지금도 활발히 업데이트하고 있는 React-Query를 사용했다고 한다.
<2. Redux에서 React-Query로 전환 이유>
Redux에서 React-Query로 전환한 이유는 리덕스의 구조와 데이터의 구분, 에러 처리로 크게 세 가지라고 한다.
결론부터 말하자면 다음과 같은 이유라고 했다.
- Redux에서 API 상태에 따라 화면을 구성하기 위해서는 별도의 도구나 상태 필요
- Redux-Saga는 의존성이 깊은 구조를 만들어 낼 수 있음
- Redux는 간단한 API 추가에도 장황한 BoilerPlate가 필요
- Redux는 API에러 핸들링 과정에서 다소 불필요한 작업이 발생할 수 있음
- 사용하는 방식, 구조, 기능에서 React-Query가 더 적합하다 판단되어 사용하게 됨
다음은 Redux에서 React-Query로의 전환 이유에 대한 내용을 설명한 것이다.
2-1) Redux의 구조
Redux 자체는 비동기 처리를 목적으로 나온 상태 관리 라이브러리가 아니라 Redux-Saga와 같은 미들웨어를 사용해야 비동기 데이터를 상태에 저장할 수 있다.
Saga에서 요청을 보내고 응답을 받아 Redux의 상태를 저장하는 과정에서 API의 상태에 따라 렌더링을 해야 하는 상황이 있을 수 있다.
예를 들어, 요청을 하는 중인지 완료된 것인지, 에러가 발생했는지와 같은 상태가 필요할 수 있다.
saga에서는 isLoading이나 isError등과 같은 상태를 별도로 제공하고 있지 않기 때문에 My 구독 상태에서는 API 응답 상태를 저장할 loadStatus라는 이름으로 상태를 관리함으로써 해결하고 있다.
Redux에서는 비동기 데이터를 처리해야 한다면 loadStatus같이 별도의 상태나 유틸리티를 만들어야 하는 반면, React-Query를 사용하게 된다면 loadStatus가 해야 할 일을 기본적으로 옵션으로 제공하고 있다.

뿐만 아니라 리덕스에서는 새로운 api가 하나 추가될 때마다 action, reducer, saga 등을 구현해야 한다.
이런 과정에서 다음 그림과 같이 간단한 API하나를 추가하는데 번거롭고, saga가 saga를 부르는 상황에서는 그 흐름을 파악하기 어려울 수 있다.

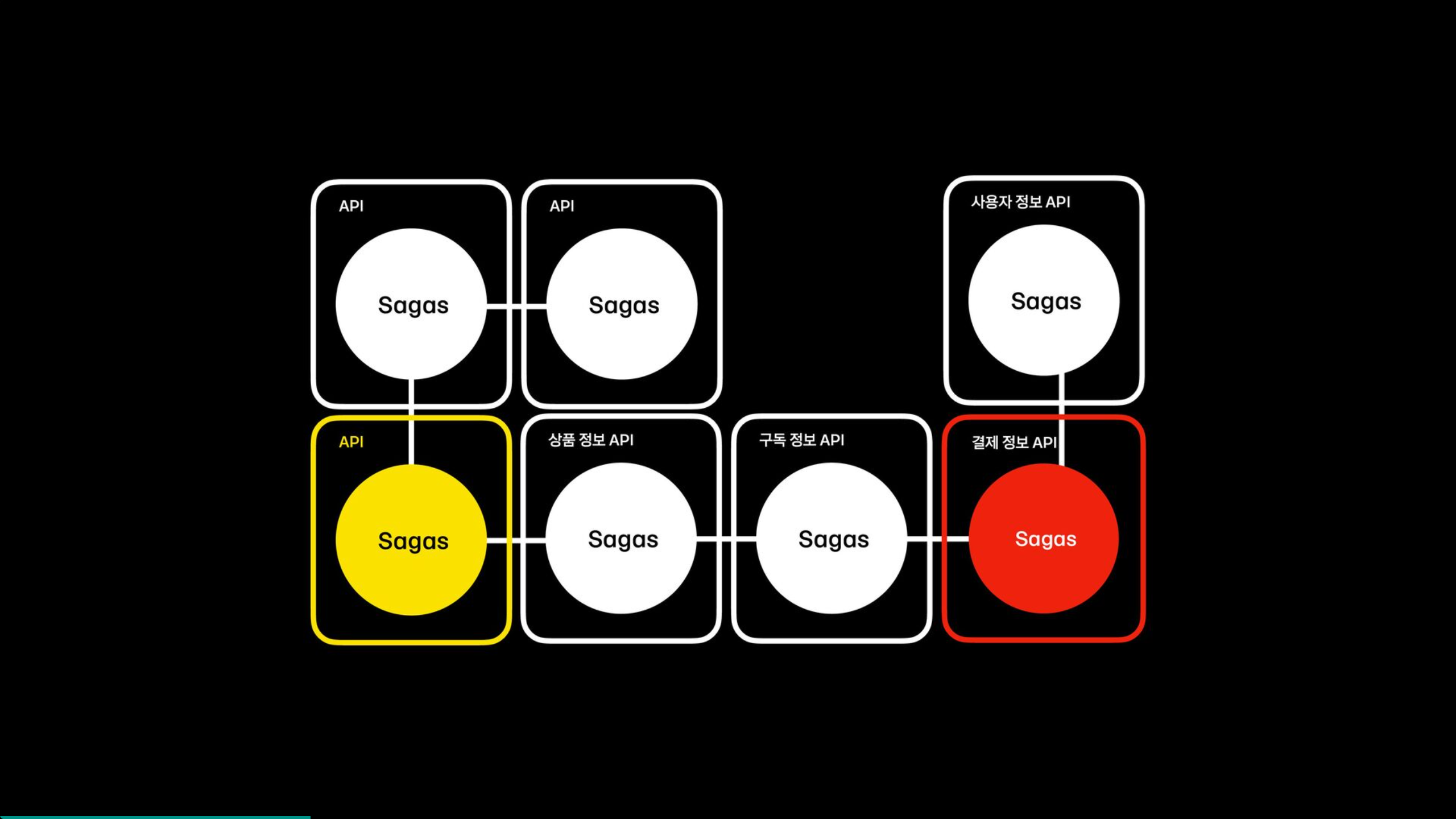
위의 그림과 코드를 보게 되면 중간에 있는 api에 문제 생기거나 포맷이 변경되어 결제정보 api에서 에러가 발생했을 때 에러가 발생한 원인을 파악하려면 결제정보 saga에서 구독 정보 saga를 타고 상품정보 saga까지 도달해야만 그 원인 파악할 수 있게 되는데, 이때, 나도 모르게 사이드 임팩트를 만들어 낼 수 있다는 문제가 있다.
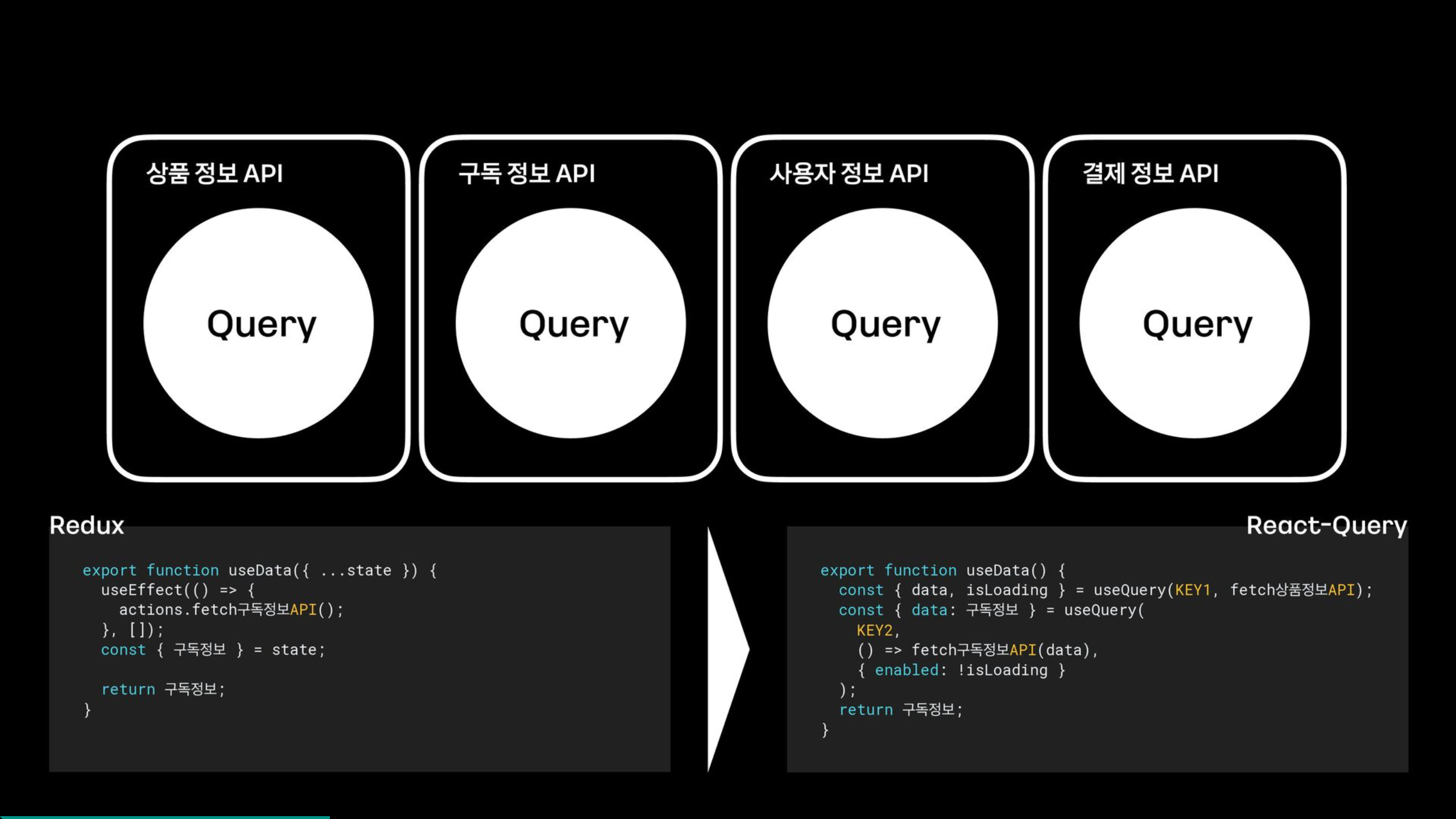
반면, React-Query에서는 각 api가 쿼리로 구성이 되고, 서로의 디펜던시는 사용하는 컴포넌트 내에서 혹은 커스텀 훅에서 전달받고 갱신하게 된다.
예를 들어 기존 Redux에서는 특정 액션이 다른 액션의 디펜던시가 있는지 파악하기가 어려웠으나, React-Query에서는 필요로 하는 디펜던시를 queryKey나 enabled 값을 통해서 직관적으로 관리할 수가 있다.
2-2) 데이터 구분
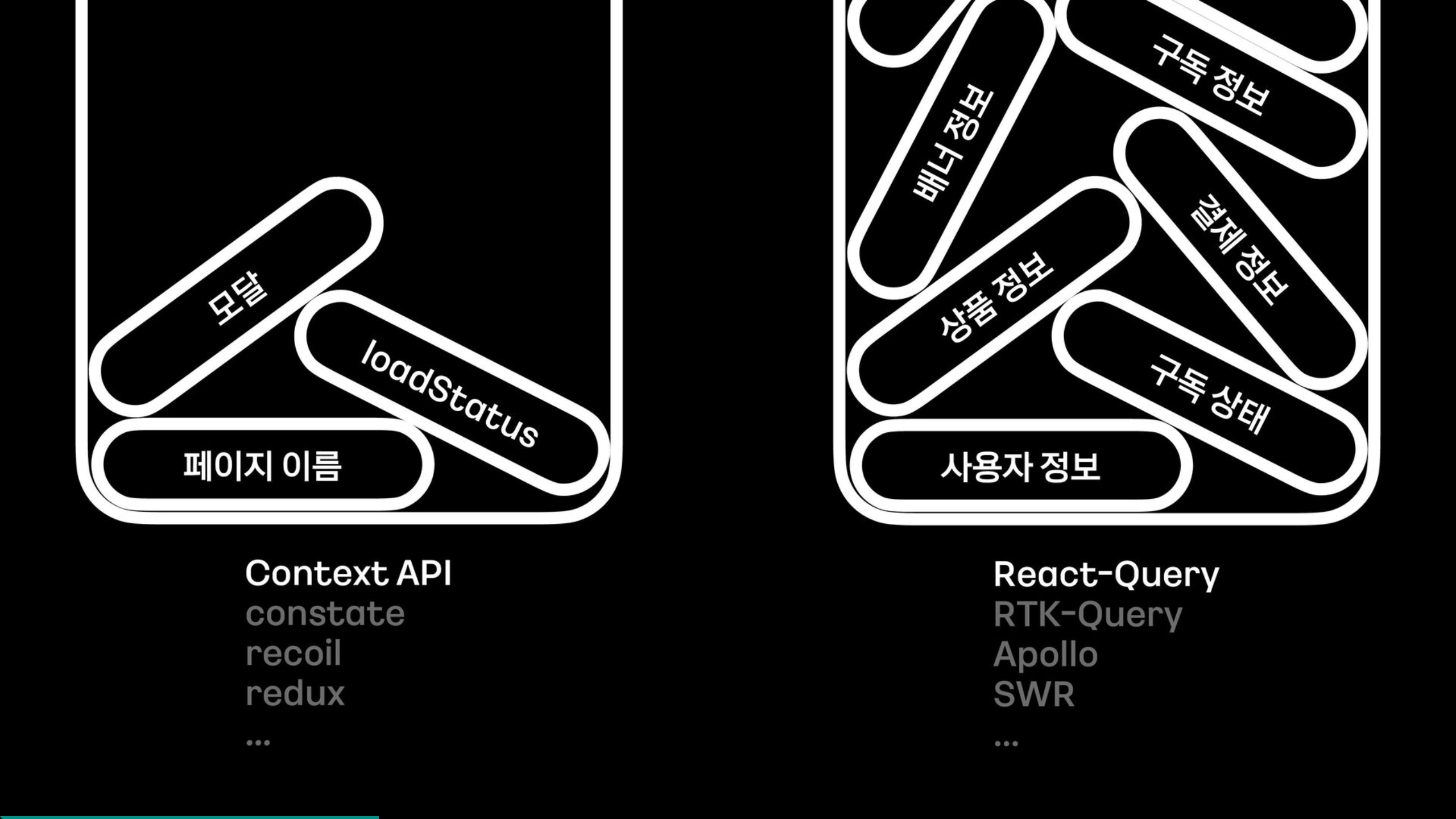
리팩터링을 위해 위의 그림과 같이 클라이언트 사이드 데이터와 서버 사이드 데이터로 나누었을 때, 서버 사이드 데이터가 훨씬 많았다. 이 두 가지 상태를 Redux 하나에 담으니 서버사이드 데이터인지 클라이언트 사이드 데이터인지 구분하기도 어려웠다. 그래서 Redux에 담았던 것을 분리하고, 클라이언트 사이드 데이터는 Context API로, 서버사이드 데이터는 React-Query로 관리하도록 하여 문제를 해결할 수 있었다.
그러면, isLoading이나 isError 같은 API 상태를 react-query에서 자체적으로 제공하기 때문에 Redux의 구조 때문에 생성했던 loadStatus는 더 이상 필요하지 않게 된다.
2-3) 에러 처리

Redux에서 에러가 발생했을 때는 위의 코드처럼 re-rendering이 발생했을 때, useEffect를 통해 처리할 수 있다.
API가 한 곳에서만 사용한다면 saga 처리 과정 중에 에러 핸들링에도 상관이 없지만, 하나의 API가 여러 컴포넌트에 사용하게 된다면 각 컴포넌트에 맞게 에러 핸들링이 필요하다.
그 결과, API 과정중에 에러가 발생하게 된다면 loadStatus 갱신으로 re-render가 발생했을 때, 컴포넌트에서 에러 처리를 하는 복잡한 구조로 되어있다.
이 과정을 React-Query로 처리하면 쿼리 옵션 중 onError 함수를 통해 컴포넌트가 re-render 되지 않더라도 에러 핸들링을 할 수 있도록 구조를 좀 더 간단하게 처리할 수 있다.
<3. React-Query로 전환 과정>
React-Query로 전환 과정에서 다음과 같은 부분을 공유했다.
- Redux hook 기반으로 전환할 때 select를 좀 더 최적화하는 방법
- REact-Query로 전환하는 과정에서 React 16에서 상태 지옥에서 벗어나는 방법
- 카카오 플랫폼 중 하나인 My 구독에서 React-Query를 어떻게, 어떤 구조로 사용하는지
- React 18로 전환하면서 어떤 이점이 발생하는지
카카오의 My구독은 고차 컴포넌트 기반의 Redux 구조를 채택하고 있었고, 일부 페이지에서는 부모 컴포넌트에서 API를 자식에게 내려주고 있었기 때문에 PropsDrilling도 발생하고 있었고, 이미 이 기능을 서비스하고 있었다는 점도 유의해서 진행했다고 한다.
API 요청하고 받는 흐름이 달라지면서 어러 사이드 이팩트가 발생할 수 있기 때문이다.
위와 같은 이유로 React-Query 과정을 1. Redux를 고차 컴포넌트 방식에서 Redux Hook 기반으로 변경하는 작업. 2. Redux 기반에서 React-Query 기반으로 전환하는 작업. 3. React 16에서 18로 전환하면서 API 상태 관리를 좀 더 깔끔하게 할 수 있도록 변경하는 작업. 이렇게 세 가지로 진행했다.
3-1) Redux를 고차 컴포넌트 방식에서 Redux Hook 기반으로 변경하는 작업
My 구독은 빠른 개발을 위해 간단하게 상태를 가져오고 갱신할 수 있도록 고차 컴포넌트를 사용한다.
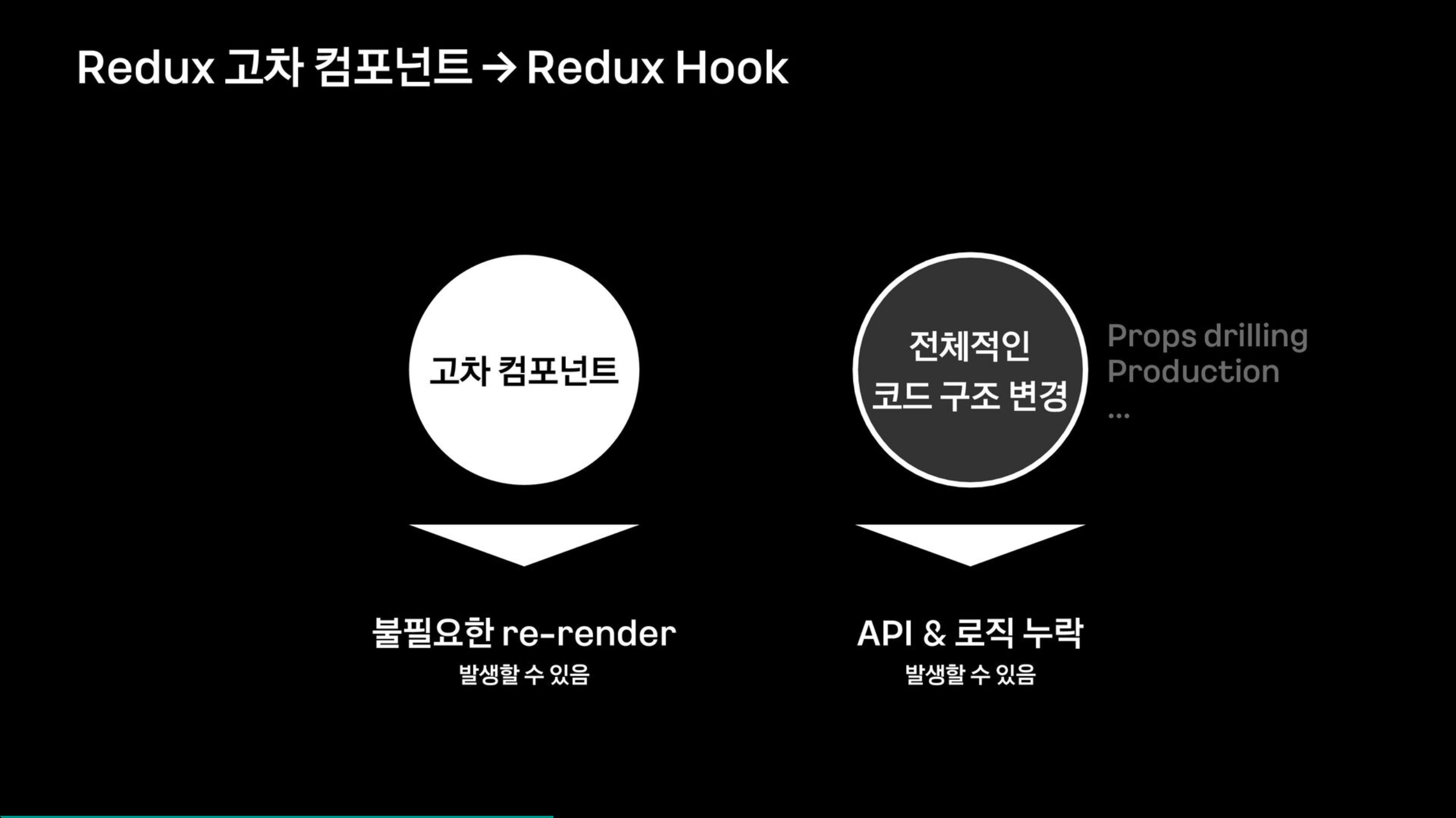
하지만 이 구조는 불필요한 re-rendering을 만들거나 React-Quer로 전환하기에는 전체적인 코드 구조가 변경되기 때문에 그 과정에서 로직 누락의 실수가 없도록 Hook 기반으로 진행을 했다.

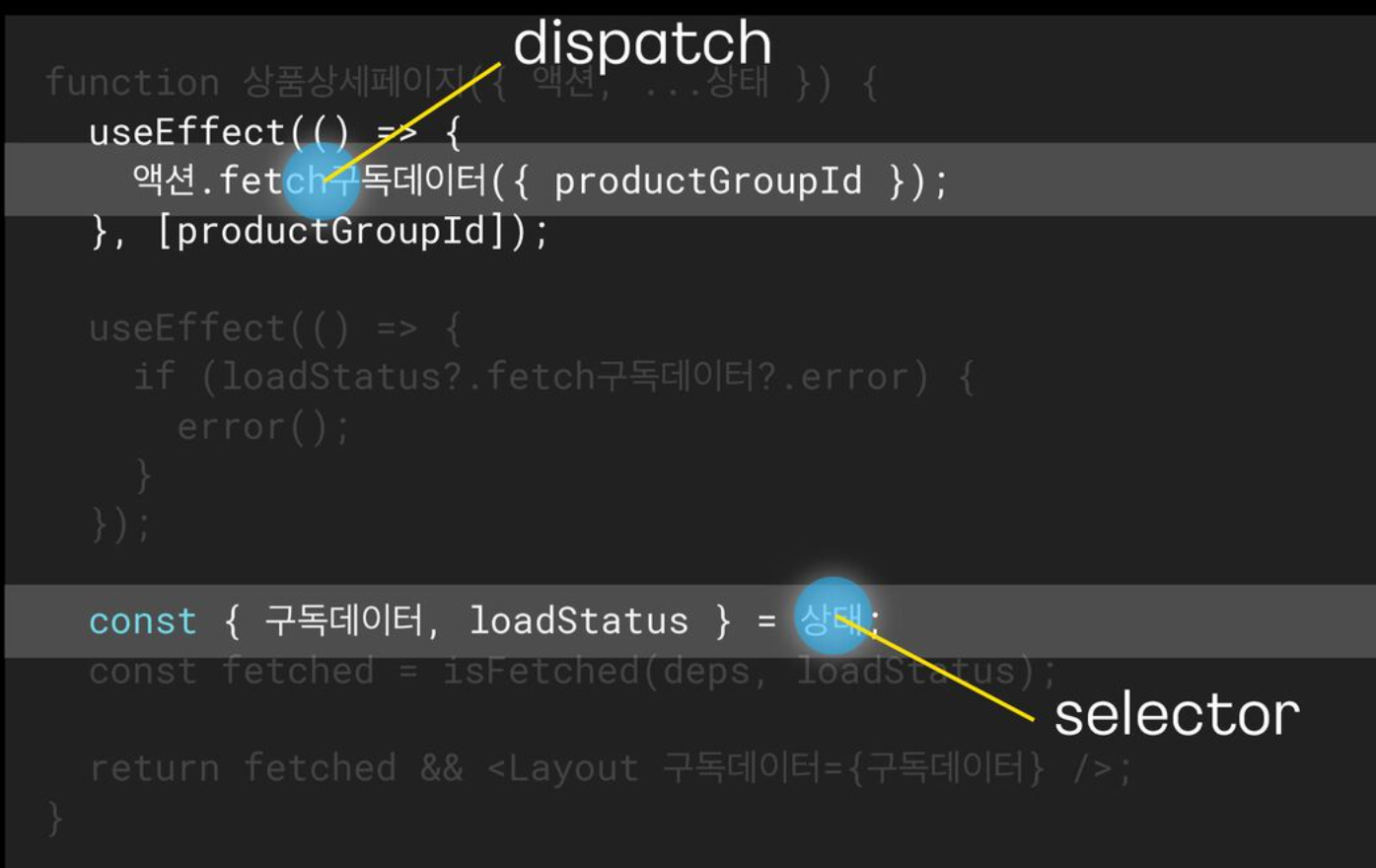
위의 코드에서 function 상품상세페이지는 API를 요청하고 화면을 구성하는 코드이고, 하단의 connectStore() 함수가 고차 컴포넌트이다. connectStore는 Redudx의 connect 함수를 한번 더 고차 컴포넌트로 처리한 함수이고, 훅기반으로 변경하려고 할 때 제거 대상이다.
Hook 기반으로 변경할 때 어떤 상태를 사용하는지, 액션을 호출하는지가 중요하고, API 상태를 확인하기 위해 loadStatus 상태도 필요하다.

function 상품상세페이지의 액션, 상태부분을 useDispatch(), useSelector()로 전환한다. 프로세서 액션과 상태를 삭제하고, 더이상 사용하지 않는 connectStore를 제거한다.
useDispatch를 사용하기 위해 dispatch Hook을 사용하고, 기존 props로 받던 상태를 useSelector로 각각 받아주도록 변경한다. 마지막으로는 dispatch 함수로 구독 데이터를 요청하도록 변경하면 고차 컴포넌트 방식에서 Hook 기반 방식으로 전환을 완료할 수 있다.
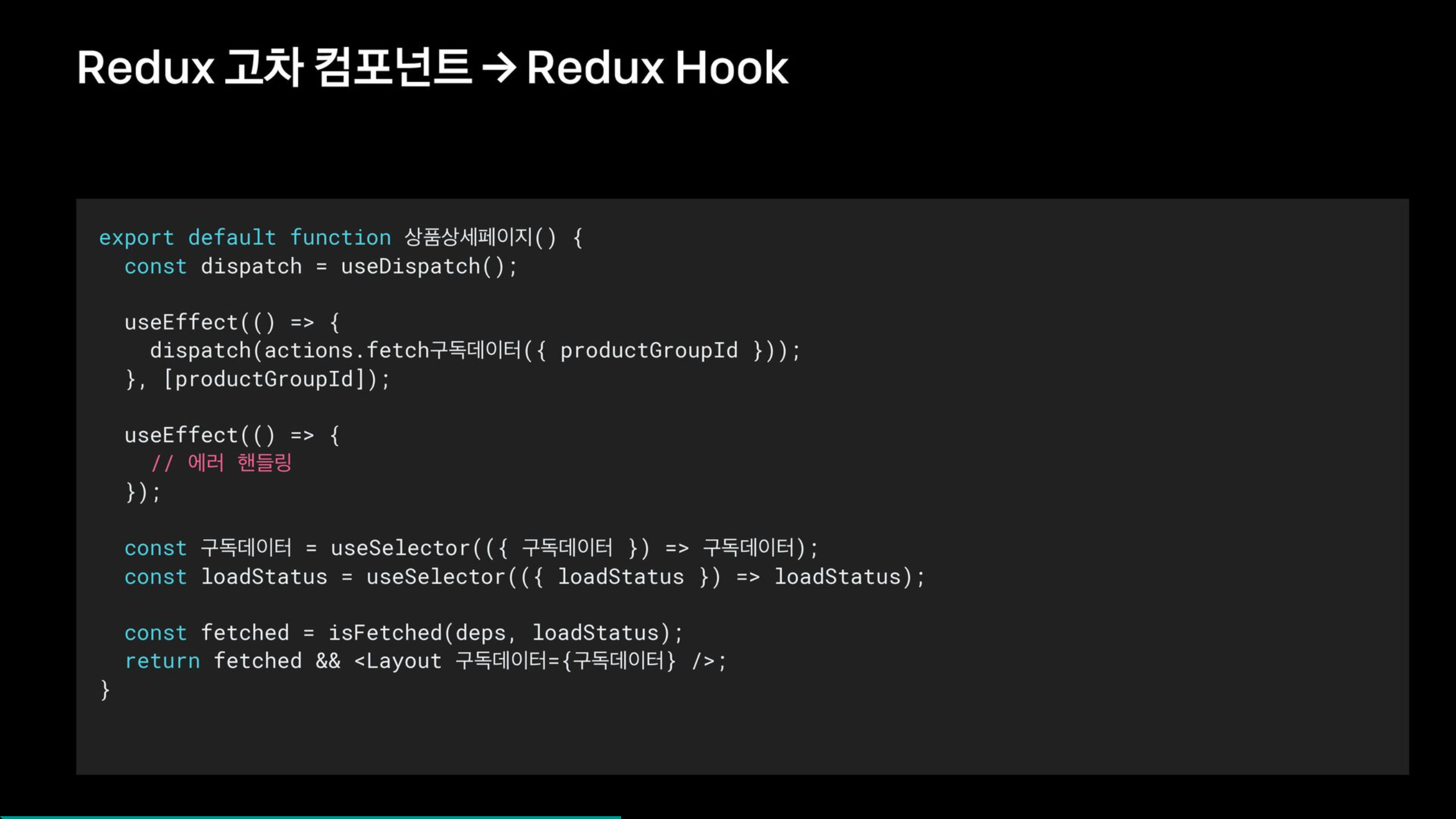
상품상세페이지 함수에서 액션과 상태가 삭제된것을 확인할 수 있으며, Hook기반으로 변경된것을 확인할 수 있다.
그러나 이 과정에서 loadStatus 문제가 발생한다.

loadStatus를 사용하는 헤더의 경우 사용자 정보 API에 대한 상태가 변경되었을 때만 re-render가 발생해야 하는데, 다른 컴포넌트에서 요청한 매대 데이터, 구독 데이터에 해당하는 API의 상태에 대해서도 변경이 발생하면서 헤더에서도 re-render가 발생하고있었다.
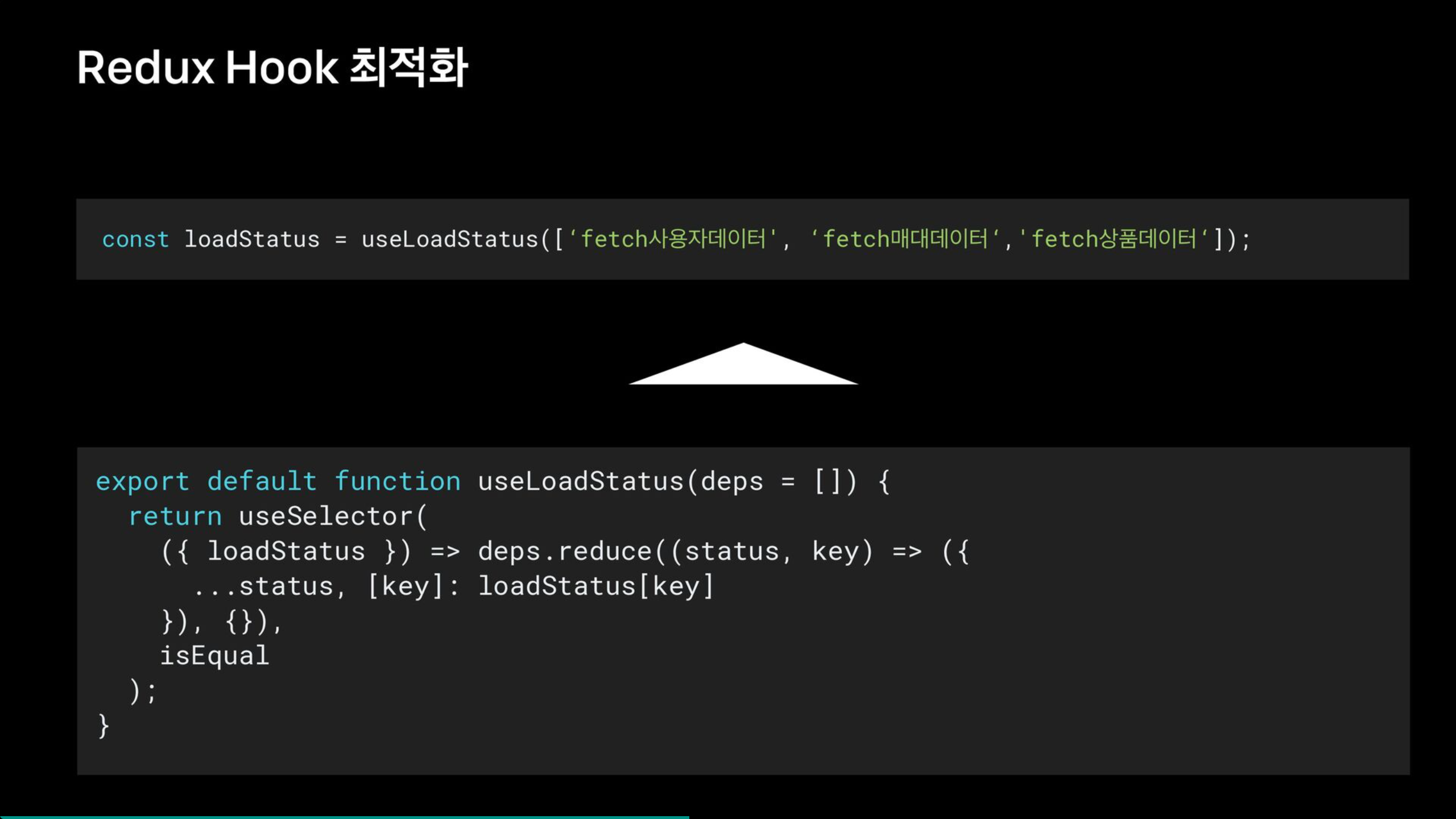
이 문제 해결하기 위해 loadStatus를 셀렉트 해서 가져오게 될 때 더 세분화해서 가져오는 방법도 고려해보았으나, 가독성과 네이밍 처리로 사용하지 않았고, 위의 코드와 같이 useStatus라는 커스텀 훅을 만들고 그 안에 필요한 디펜던시 목록을 받아 필요한 API 상태만 반환하도록 수정하여 해결했다.
그 결과 가독성이 올라갔고, re-render 횟수가 절반 가까이 줄었다고 했다.
3-2) Redux 기반에서 React-Query 기반으로 전환하는 작업

위의 코드는 앞의 Hook기반에서 React-Query로 변경한 코드이다.
기존 loadStatus대신 React-Query 기본 옵션인 isLoading을 사용했고, useQuery를 사용함으로써 dispatch와 selector를 대신하게 된다.
기존 useEffect내에서 에러핸들링을 하던 코드를 onError 옵션을 통해서 핸들링 할 수 있게 되었다.
그러나, React16으로 처리했다는데에서 문제가 발생한다.
지금은 하나의 API만 있었기 때문에 간단했지만, API가 하나씩 늘어갈 떄마다 API의 상태를 관리하기가 어렵고 가독성이 떨어진다. 이런 문제를 해결하기 위해 useQueriesLoading이라는 커스텀 훅을 다음과 같이 생성했다.

위의 코드를 보면 queryClient로부터 등록된 쿼리를 가져오고 현재의 등록된 쿼리 개수를 state에 저장한다음 렌더링 될 때마다 로딩하는 쿼리가 있는지 확인한다. 또, idle 상태에서 로딩으로 변경될 수 있는 상황을 대비해 idle 개수만큼 로딩이 없다는것을 지연시켜 react 16에서도 서스펜스 없이 상태지옥에서 벗어날 수 있었다.
3-3) React 16에서 18로 전환하면서 API 상태 관리를 좀 더 깔끔하게 할 수 있도록 변경하는 작업
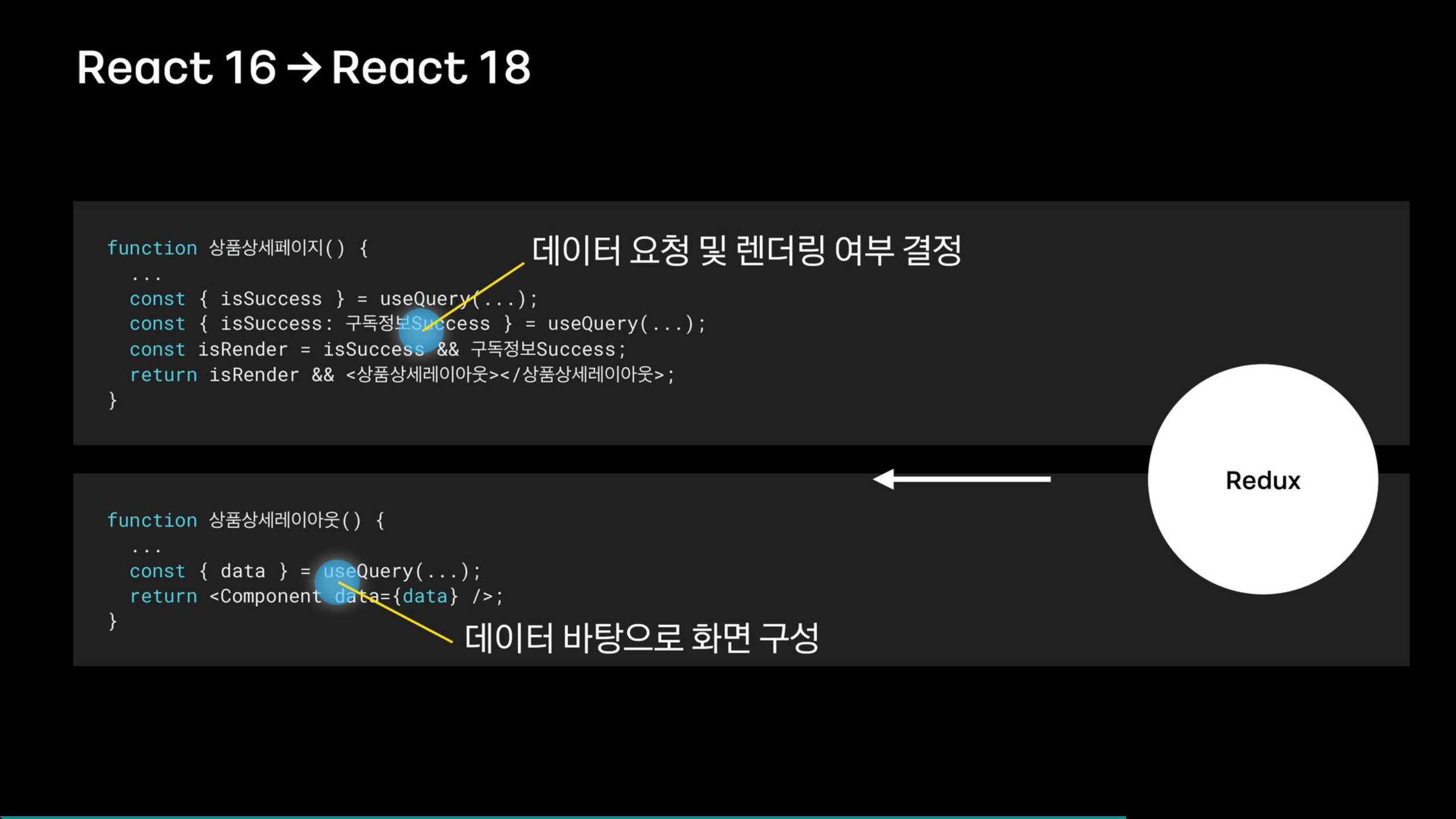
위의 코드에서와 같이 My구독은 컴포넌트의 복잡도를 낮추기 위해 세페이지와 레이아웃 컴포넌트로 분리해놓았다. 컴포넌트 복잡도가 높았던 이유는 API 응답이 오고 나서 화면을 구성해야했기 때문이다.
페이지에서는 데이터 요청 및 렌더링 여부를 결정하고, 레이아웃은 데이터를 바탕으로 화면을 구성하는데, 이 구조는 Redux를 사용하면서 적용한 패턴이다.
이부분에서 중복 요청이 발생할 수도 있고, 그 과정에서 불필요한 re-render도 발생할 수 있다.
여기서 react18의 suspense도입으로 이 문제를 해결 할 수 있다.
API 요청하는 컴포넌트에서 더이상 API의 상태에 대해 고려할 필요가 없어졌다.

위의 코드처럼 가독성이 높게 구성할 수 있거나, 단순히 API를 요청하고 응답에 따라 렌더링하던 페이지 컴포넌트는 레이아웃 컴포넌트와 합성할 수 있게 된다.
<4. 정리>
React-Query를 사용했을 때의 장점과 아쉬운 점은 다음과 같다.
- 장점
- Hook 기반으로 비동기 처리를 할 수 있고, 캐싱 지원.
- 비동기 처리를 위한 유용한 도구 제공.
- 서버데이터가 자주 바뀌는 경우, 최대한 최신데이터를 보여줄 수 있는 백그라운드 패칭 지원.
React-Query 도입 시, 이러한 상황이면 고려해봐야한다.
- 서버사이드 데이터가 거의 없는 경우, React-Query보다 다른 라이브러리가 더 적합할 수 있다.
나중에 서버사이드 데이터가 더 많아질때 React-Query와 같은 비동기 상태 관리 라이브러리를 적용해도 늦지 않는다.
- React 18에서는 단순히 비동기 처리 상태를 제공하는 기능때문에 사용한다면 고민해볼 필요가 있다.
suspense를 사용하게 되면서 더이상 API가 오고있는 상태인지가 중요하지 않게 되었기 때문이다.
- 아쉬운 점
- Mutation은 한 번만 호출하기 위해 Wrapper 함수가 필요
- UI 테스트를 진행하게 될 때 Mock API가 필요할 수 있다.
- 항상 서버 데이터와 같은 데이터를 바라보는 것이 좋은 것은 아님.
- 전체적인 데이터 흐름을 파악하기 어렵다는 느낌을 받기도 한다.
이렇듯 우리 제품에서도 서버사이드 데이터가 많아지거나, 사용자들의 요구사항이 늘어났을 때와 같은 경우, React-Query를 도입하면 좋지 않을까 생각하게 되는 세션이었다.
이상 ifKakao dev 컨퍼런스를 듣고 정리한 내용이다.
참조: ifKakao dev(https://speakerdeck.com/kakao/nune-boiji-anhneun-gaeseon-mygudogyi-reduxeseo-react-query-jeonhwan-gyeongheom-gongyu?slide=124
'Technology > Tech Insight' 카테고리의 다른 글
| Continual Learning (0) | 2022.12.21 |
|---|---|
| 정보보안 OWASP : Open Web Application Security Project (1) | 2022.12.16 |
| Design system with tokens (0) | 2022.12.08 |
| UX 사용자에게 습관을 형성해 제품의 사용률을 높이는 방법 (0) | 2022.12.08 |
| [소프트웨어 보안약점 진단] 취약한 API 사용 (0) | 2021.12.23 |





